
RadonDB作为一款优秀的分布式数据库产品,离不开这几大组件:
RadonDB的存储由MySQL存储节点提供,这很正常,这些存储节点还负责了计算工作。从这个角度上来说,RadonDB还不是很典型的分布式数据库系统。这种架构上,计算实际上并不是由RadonDB来提供的,而是由MySQL提供的。
RadonDB的设计上还有一个精巧的地方,就是利用了TokuDB存储了全量数据,比照较复杂的计算,需要join的地方,都由这个全量存储来提供。因而RadonDB看着不太像一个典型的分布式存储系统,不过青云实现了MySQL集群的Raft协议,这一点还是很值得称赞的。
昨天夜里和今天白天我读了很多有关Raft协议的资料,那么今天还是来看看RadonDB是如何实现MySQL的Raft的。
RadonDB的Raft组件叫做Xenon,在github上也有源代码。先来看看整体的架构图:
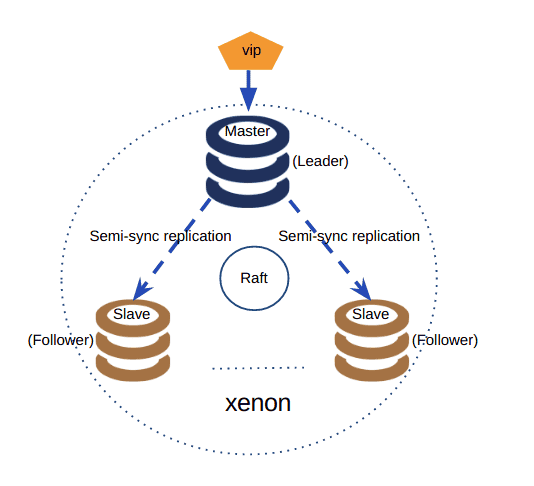 架构图
架构图一个Raft集群应该有三种状态:Leader,Candidate和Follower。Xenon的代码是这样实现的:
// Leader tuple.type Leader struct { *Raft // the smallest binlog which slaves executed by SQL-Thread relayMasterLogFile string // leader degrade to follower isDegradeToFollower bool // Used to wait for the async job done. wg sync.WaitGroup // the binlog which we should purge to nextPuregeBinlog string purgeBinlogTick *time.Ticker checkSemiSyncTick *time.Ticker // leader process heartbeat request handler processHeartbeatRequestHandler func(*model.RaftRPCRequest) *model.RaftRPCResponse // leader process voterequest request handler processRequestVoteRequestHandler func(*model.RaftRPCRequest) *model.RaftRPCResponse // leader send heartbeat request to other followers sendHeartbeatHandler func(*bool, chan *model.RaftRPCResponse) // leader process send heartbeat response processHeartbeatResponseHandler func(*int, *model.RaftRPCResponse)}Leader要做的事情有两件:
这些都是通过RPC来实现的。代码中首先去新建了一个Leader:
// NewLeader creates new Leader.func NewLeader(r *Raft) *Leader { L := &Leader{ Raft: r, } L.initHandlers() return L}现在看看这些都是干什么的吧。
入选举成功以后,一个节点成为Leader,这个时候就会去调度这个方法来新建一个Leader角色。其实新建Leader也无非就做了这么几件事:
// leader handlersfunc (r *Leader) initHandlers() { // heartbeat request r.setProcessHeartbeatRequestHandler(r.processHeartbeatRequest) // vote request r.setProcessRequestVoteRequestHandler(r.processRequestVoteRequest) // send heartbeat r.setSendHeartbeatHandler(r.sendHeartbeat) r.setProcessHeartbeatResponseHandler(r.processHeartbeatResponse)}这段代码让我看着有点恍惚,很像Java的setter方法,这些方法将各种request发送了出去,但是我有点不知道为什么要解决投票的请求,按理说这个时候投票都已经结束了,开始了自己的任期,以后假如有机会调试代码再看看。
今天先挑一个发送心跳的方法来看看:
// leaderSendHeartbeatHandler// broadcast hearbeat requests to other peers of the clusterfunc (r *Leader) sendHeartbeat(mysqlDown *bool, c chan *model.RaftRPCResponse) { // check MySQL down if r.mysql.GetState() == mysql.MysqlDead { *mysqlDown = true return } // broadcast heartbeat r.mutex.RLock() defer r.mutex.RUnlock() for _, peer := range r.peers { r.wg.Add(1) go func(peer *Peer) { defer r.wg.Done() peer.sendHeartbeat(c) }(peer) }}由于是基于MySQL节点做的Raft,因而首先要检查mysqld能否存活,假如死掉了也就没有发送心跳的意义了。这里要说明的是,不是mysql向外发送心跳,是Xenon,因而肯定要检查mysqld的状态先,mysqld挂掉了,就不发心跳了,即可以触发新一轮选举了。
发送心跳的时候要遍历所有节点,由于要给所有节点发心跳,每遍历一个节点,就要给WaitGroup中添加1,waitGroup可以保证goroutine安全的结束。
这之后自然就是调用发送的方法,向集群内广播心跳了。
Go语言有个很有意思的地方叫做函数类型。也就是说可以把变量指定成函数类型,比方这样:
package mainimport "fmt"func test(param string) { fmt.Println(param)}func main() { t := test t("quan")}我暂时还没有想明白函数变量的好处,都说是让代码变得更灵活。
这段代码中还有一个waitGroup,参考一下下面的代码:
package mainimport ( "fmt" "sync")var wg sync.WaitGroupfunc test(param int) { defer wg.Done() fmt.Println(param)}func main() { for i := 1; i < 10; i++ { wg.Add(1) go test(i) } wg.Wait()}注意,Add和Done肯定要配对,不然肯定报deadlock错误。
现在画张图看看原理:
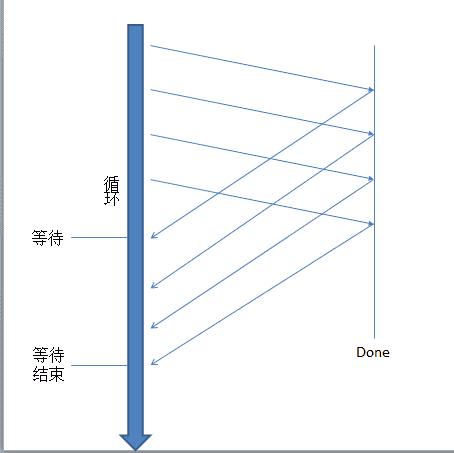 并发等待
并发等待所有的现成完成之后都会去等待,并在此时将wg的计数器减1,计数器被减到0时,等待结束。
其实要是学习Raft的实现的话,我这个系列可能还得再写一段时间。
